今年7月到9月,我以master_deng的队名和师弟一起参加了 阿里全球调度算法大赛 GSAC 2018 ,成绩分别为:初赛 12/2116,复赛 11/100。 比赛结束近一个月了,这里总结一下比赛过程。这是第 1 部分 - 比赛简介。
1. 简介
阿里全球调度算法大赛 Alibaba Global Scheduling Algorithm Competition - GSAC2018 分初赛、复赛、决赛三个阶段。 初赛和复赛在阿里云的天池平台线上进行。初赛前 100 名的团队进入复赛,复赛的前 10 名获得决赛资格,最终只有 6 支队伍进行决赛 —— 这 6 支队伍到杭州阿里巴巴总部 进行现场答辩。 我们以master_deng的队名三人组队,初赛排名是 12/2116;之后由于比赛规则,由两人继续参加复赛,排名是 11/100,止步于此。 从复赛的排行榜看,我们的成绩与前面的队伍的差距还是很大的。

1.1 初赛
场景
初赛阶段从2018年6月初开始,到8月14日止,场景是 大规模集群中在线应用的部署 。 具体说,有 68k 多个 Pouch容器 ,分属于 9k 多个持续运行的在线应用,需要部署到不超过 6k 台机器上,限制是不能超过集群总的资源容量,还要满足应用间的干扰约束规则,最终实现较好的资源利用率和机器间的负载均衡。 需要注意的是,
- 这是阿里内部的集群环境,而且以 Pouch 容器作为资源管理单元,不是 阿里云的虚拟机环境
- 应用是持续运行的,不考虑时间因素,只为容器选择合适的机器,所以称为 部署(Deploy),或者说 资源管理(虽然也常说成是 调度,而且中文的 调度 含义确实有此含义,但对应的英文单词 Schedule 通常指 时间相关的安排,必要时要区分开。)
比赛以分时的曲线的形式给出了应用的资源使用模型(CPU,内存)。刚开始有些想法:在运行中的某个时刻,将某个应用迁移到其它机器,从而将高峰和低谷时段不同的应用的资源曲线错峰填谷搭配,提高资源利用效率。不过在初赛解读(见附件PPT,及视频)中,比赛方 否定 了这个想法,虽然理论上看起来不错,但不符合实际,得不偿失。这样也让问题简化了不少。
比赛数据的初始状态中(集群的 初态),有些应用的容器实例已经部署到机器上了,还有一些等待部署,即机器不是完全空闲的状态。
- 选手可以保留初始部署,在此基础上继续部署其它实例
- 也可以完全忽略初始部署,从所有机器都是空闲的状态开始实施自己的算法;显然这样才能贯彻选手的算法。
最终选手提交的是一个<实例Id, 机器Id>的列表,即部署/迁移动作列表。但并 不是 简单地给出实例及其最终部署的目标机器(集群的 终态),而是从 初态 到选手得到的 终态 的全部过渡动作,而且每步动作都要满足资源容量约束和应用干扰约束。好在比赛不限制动作的总数。
虽然部署的是在线应用,但 部署过程 本身是 离线的,即所有应用的资源模型都已知,据此计算出优化的终态,实施部署,之后集群才算开始运行;而不是在集群运行期间响应用户提交的新应用(在线部署)。离线部署对计算时间不太敏感,可以长一些,所以比赛没有硬性限制计算时间。
实际的集群是持续运行的,而且会有新应用提交,也有旧应用下线,但集群中的大部分应用是较稳定的。可以根据资源监控的历史数据对这些已知的应用建模,并且定期(比如每天)重新计算并调整集群的最优部署。初赛解读 中提到比赛的场景来自阿里内部的集群资源管理系统 Sigma。
因为 Sigma 兼容 Google 的 Kubernetes (k8s) API,之前我认为两者的资源管理方式也是差不多的,即 在线资源管理 。结合这次比赛,以及初赛解读中提到的 Sigma 是面向终态的架构设计,看来两者还是有很大差别的。 Sigma 补上了 k8s 缺失的 全局重调度 这个很有实践意义的重要功能。 k8s 有一个孵化项目 descheduler,其设计目标也是重调度,可以参考 相关讨论 #12140。 离线部署功能也可以从 Sigma 中划分出来,作为单独的组件;但两者有不少功能是可以共用的(比如约束检查),所以我认为合在一起更合适些。
机器分配(Assignment)问题是典型的 组合优化问题,也可以表示为装箱问题 Bin Packing,或直接说 Packing。规模较小的问题可以使用 Gurobi 或 CPLEX 等商业求解器按 0-1整数规划 求解。但比赛的数据规模超出了求解器的能力;另外,目标函数是指数函数,也难以直接使用求解器。
使用装箱的近似算法,比如首次适合算法(First fit,FF),肯定可以排在初赛的前 50 名,顺利进入复赛。 决赛的 6 支队伍仅有 4th - SuperUncle 只用 Best fit 算法,其它 5 支队伍都使用了某种 局部搜索,除了随机搜索(6th - 地球漫步,3rd - rivulet,2nd - greydog),还有 模拟退火 Simulated Annealing,SA (5th - yxgy,1st - 我就看看不提交),不过 1st - 我就看看队 在答辩中提到,他们的 SA 并没有改变温度,实际上也是随机搜索;yxgy 的 SA 跟 我就看看队 的是不同的。
机器
集群共有 6000 台机器(Machine,不致混淆时,简记为 m),按资源容量(Capacity)分为 2 种,各 3000 台,Id 是连续的整数。 从机器数量来看,集群应该算是中等规模吧。 
应用和实例
所谓在线应用(App),主要就是 Web 应用。共有 9338 个应用。应用是匿名的,通过 App Id 来区分。App Id 也是连续的整数。 每个应用有不同数量的实例(Instance,简记为 inst)。每实例就是一个 Pouch 容器。共有 68219 个实例。Inst Id 也是整数,但 不是 连续的。 平均每个应用有 7 个实例,但实际上应用的实例个数是很不均衡的:
- 最“大”的应用有 610 个实例,最小的只有 1 个实例
- 大部分(~62%)应用仅有 1~2 个实例;约 10% 的(1061个)应用有 > 10 个实例,其中仅 104 个应用有 ≥ 100 个实例
应用干扰约束
应用之间有干扰(Interference,简记为 X)约束,表示为 <App_A, App_B, k> 这样的规则。其含义是:若某机器上已存在 App_A 的实例,那么允许存在的 App_B 的实例个数不能超过 k 个。
- 若 k=0 ,就表示 App_A 不能与 App_B 共存在同一台机器;若机器上没有 App_A 的实例,这条规则就不影响 App_B 的部署了
- 若 App_A = App_B ,即两者是同一应用,由于规则生效的前提是机器上至少有一个 App_A 的实例,所以
<App_A, App_A, k>这样的规则实际是限制同一机器上 App_A 的实例总数不超过 k+1 个;对这种规则,即便 k=0,机器上还是可以部署一个 App_A 的实例的,当然也可以不部署 <App_A, App_B, k>与<App_B, App_A, m>,即正,反向的约束 没有直接的关系。也就是说,每个应用都有自己的偏好,App_A 可能很嫌弃 App_B,但 App_B 却对 App_A 毫不在意,可以m ≠ k,甚至可以不存在<App_B, App_A, m>这样的约束- 向机器部署一个 App_B 的实例时,既要检查这台机器上 App_B 嫌弃的那些应用(可能是 App_C,App_D 等)已存在的实例个数不超过 App_B 的约束;也要检查若增加 App_B 的一个实例,是否会违反那些嫌弃 App_B 的应用(比如 App_A 等)的要求
- 共有 35k 多条约束规则,仅有少数应用有几百条规则,最多的一个有 600 多条,有约 2/3 的应用则没有规则
初赛解读中提到了 亲和/反亲和 约束,实际上这里的规则是硬性的,适合表达 反亲和(干扰)。
应用资源约束
属于同一个应用 的实例有相同的 资源使用模型,包括下面几种资源,共用 200 个数值(维度)来描述:
- 98个 浮点数 表示 CPU 分时使用量,核数
- 98个浮点数表示 内存 分时使用量,GB
- 1 个整数表示 磁盘 使用量,GB
- 3 个整数表示 P,M,PM 三个阿里内部定义的虚拟资源,用来表示应用重要性,比赛中影响不大
98 个点的分时曲线大致 ~15 min 记录一个点,描述了应用实例在一天 24 h (实际是 24.5 h)的资源使用变化情况。
下图是将所有应用的CPU和内存资源使用量分别乘以该应用的实例个数后,分时刻求和,再除以集群资源总容量得到的 整体分时波动曲线。
- 可以看到内存的利用率比较平稳,~37%
- CPU有明显的峰谷,最大 ~38%,最小 ~18%,平均 ~25%
此外,整体的硬盘使用率 居然达到了 ~94 %, 比CPU和内存还紧张! 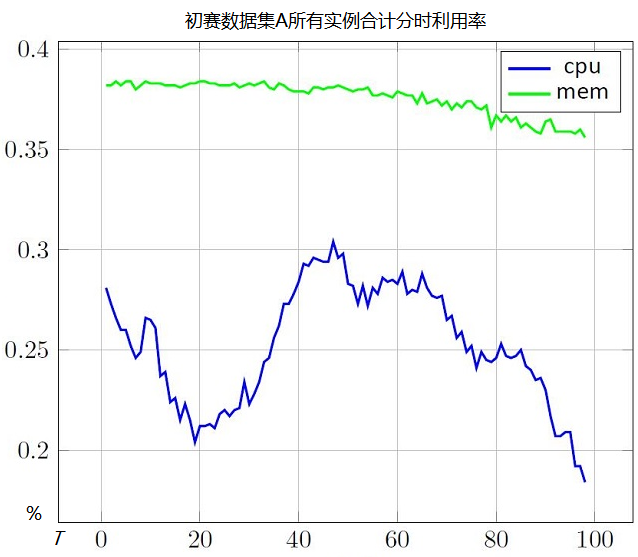
应用之间在资源使用量和分时波动上都存在显著的不均衡:大部分的应用使用的资源很少,而且一天内基本没有波动。少数关键应用使用了大部分资源,而且有明显的波动趋势。
- 分时:对 CPU,标准差 StdVar < 0.5 的 共有 46048 个(~68%)实例,分别属于 8613 个(~92%)应用; 对内存,StdVar < 0.5 的 共有 50095 个(~73%)实例,涉及 7283 个(~78%)应用
- 总量:最紧张的硬盘资源用量,分为 40 GB 到 1024 GB 共 16 个离散值,大部分集中在 60 GB,占总实例个数的 78.5 %;超过 600 GB 的实例个数仅有 41 个,占 0.06 %
很容易想到分时曲线是从资源监控的历史数据统计出来的。模型的准确性总是值得讨论的,但比赛中不考虑这个问题。另外,上面提到不少应用的资源使用量在一天内没有波动,可能没有对全部应用建模,而只对部分 关键应用 建模了吧。
问题
平均下来每台机器有11个实例。考虑到成本,要尽量 少占用 机器。比赛的问题就是 把 68k 多个实例部署到不超过 6000 台机器上,具体说,
- 目标:所有实例都部署到了机器上,而且使用的机器数量越少越好
- 资源约束:每台机器上部署的应用实例使用资源之和不能超出机器资源容量
- 干扰约束:此外还要满足应用间的干扰约束规则
每个实例部署时都不能违反这两个约束,最终整个机器的状态也不能违反。 若只考虑资源约束,可以认为是一个大规模的 多维向量装箱 问题,维度是200维,而且箱子(机器)是异构的。
优化目标
具体的 优化目标 (Total cost score,简记为 score,越小越好) 是:
其中,$T=98$,是分时数据点的个数; $M=6000$,是机器总数;$s^t_j$ 代表机器 $j$ 在时刻 $t$ 的成本分数。 交换两个求和的顺序后,说明可以先分别计算 各机器在 98 个时刻的成本分数平均值 ,然后再合计集群中所有机器的成本。
如果机器 在时刻 没有实例部署,则 $s^t_j=0$ ;(*注) 否则, $s^t_j = 1 + \alpha(e^{\max(0,c-\beta)} - 1)$ 其中,$c$ 是机器 $j$ 在时刻 $t$ 的 CPU 利用率;$\alpha, \beta$是惩罚系数,分别为 $\alpha=10, \beta=0.5$。 如果提交结果不符合规范,成本分数为 $10^9$。成本分数 越低 越好。
*注:成本分数仅考虑 CPU 资源。 若 CPU 利用率为 0,按公式计算出 ,即 没有部署任何实例的空闲机器 的成本分数是 1。另一方面,若一台机器的 CPU 使用率在所有时刻均不超过 50%,其成本也是 1。为了区分两者,所以 规定空闲机器的成本为 0。 上面提到,每台机器可以分别计算在 98 个时刻的成本分数平均值 :如果所有时刻的 CPU 利用率都不超过 50%,机器的成本分数 也是 1;只要有一个时刻的 CPU 利用率超过 50%, 必然大于 1。
若 CPU 利用率不超过 50% ,则成本分数就是 1;超过 50% 后,就呈指数增长了。下面是成本公式的反函数,
若 ,则 ;即当 CPU 利用率从 50% 增加到 59.5%,成本分数就 翻倍 了。若 ,则 。
- 对 92 个核的机器,从 50% 到 59.5%增加的 9.5% 利用率对应了 8.74 个核;反之,如果使用一台空闲机器 m,只要 m 的 CPU 利用率不超过 50%,也只增加 1 分,但相当于增加了 46 个核。
- 对 32 个核的机器,9.5% 的利用率对应 3.04 个核;50% 的利用率相当于 16 个核。
因此,优化目标是希望:
- 使用的机器尽量少
- 已经占用机器的 CPU 利用率尽量不超过 50%,且机器间的 CPU 利用率尽量均衡
- 由于只比较利用率,对相同的百分比,大型机器提供的资源数量更多,因此应充分使用大型机器
初始部署
初始数据中,有约 30000 个(~ 44%)实例已经部署到 ~2500 台机器上了。初始部署的质量还是很高的:硬盘的利用率基本都在 90% 以上,甚至有的是 100%,而且都没有超出资源容量约束。 从成本分数上看,已部署的大型机器中,仅有一台的成本分数 > 1.0,即有些时刻的 CPU 利用率超过了 50%;而小型机器则有 400 多台的成本分数 > 1.0 。如果初始部署来自阿里的真实环境,那么看来算法对机器的异构性处理得不太好。
另外,有一百多个实例与所在机器上的其它应用的实例存在 违反干扰约束 的情况。看来发现了一个 Bug ;-)
评分代码
由于大家对赛题理解存在偏差,一开始很多队伍的提交不满足格式要求,好在比赛方在7月9日开源了评分代码。 对上面提到的一百多个实例违反干扰约束的实例,我们开始是直接 跳过 这样的实例,保证机器上部署的实例都是满足两个约束的。但评分代码则 忽略约束,强制 将实例部署到机器上。参考评分代码,我们修正了这个处理逻辑。
数据和评分代码都公开了,比赛结束后,感兴趣的同学还可以尝试一下。
初赛数据集 B
初赛数据中应用的 硬盘资源比 CPU 和内存要紧张得多,以至于仅考虑硬盘资源维度就可以得到比较好的部署结果。 7月5日,初赛刚开始排名,4th - SuperUncle 就给出了 5506 的最优解,随后 5506 分的队伍越来越多。月光鸣下(1st - 我就看看不提交) 在初赛结束后给出了 通过硬盘资源构造初赛最优解的思路,但还要在此基础上满足应用资源约束和干扰约束。 于是,比赛方在 7月26日 添加了初赛数据集 B。 相比最初的数据集 A,仍有 6000 台机器,大小各 3000 台;应用数仍为 9338 个;实例数增加了 5 个,为 68224 个。 发生变化的有:
- 机器的 CPU 和内存等容量没有变化,但硬盘容量增加了
- 应用的 硬盘使用量不变,但因为机器硬盘容量增加了,导致硬盘利用率减小了(~39%);应用的 CPU 和内存的使用量均 增加了,利用率也增加了(Max/Min/Avg:CPU ~55%/32%/45%,内存 ~60%/59%/60%);分时上,内存使用率非常平稳,而 CPU 仍然是明显的峰谷趋势
- 所有应用都至少有 1 条干扰约束规则了,但仍然是不均衡的,大部分应用只有 1 条约束规则

初始状态已经部署了 61k 多个实例,仅剩 6900 多个实例尚未部署。因为 CPU 用量增加了,大部分机器的成本分数都超过了 1.0。这次没有违反资源容量约束或干扰约束的情况。
1.2 复赛
复赛从 8月15日 至 9月7日,比初赛时间短一些。这就要求选手初赛阶段的算法比较通用。复赛直接提供了 5 份数据集,除了初赛的在线应用,还增加了离线任务,场景也就变成了 在线应用(App)和离线作业(Job)混合部署(混部)。
离线作业
这里首先明确一下名称:比赛的介绍中称为离线 任务,但这里将其称为离线 作业(Job)。一个作业(Job,如一个完整的 MapReduce 程序)包含多个任务(Task,一个执行阶段,如 Map 任务、Reduce 任务等)。
每个任务对应数据文件 job_info.x.csv 中的一行,其中 x 是 a,b,c,d,e 之一(job_info.e.csv 是空文件)。下面是 job_info.a.csv 的前 5 行,每行的格式为 离线任务Id, CPU 用量, Mem 用量, 实例数, 执行时间, 前驱任务Id列表。
8886-18,0.50,0.25,111,98,
8886-14,0.75,0.38,20,88,
6801-2,0.50,0.50,3,128,
6801-3,0.50,0.25,13,122,6801-1,6801-2
6801-1,0.50,0.25,37,124,
- 其中 Task Id 如
8886-18,赛题介绍中没有明确(导致答辩时各队伍的叫法都不同),这里我们把短横前面的部分称为 Job Id,如8886。同一作业的任务在数据文件中不一定是连续的,也不一定是顺序出现的,比如上面的例子。5 个数据集的 作业数/总任务数(行数) 分别为 a: 1085/5241, b: 1094/5637, c: 546/2840, d: 478/2250 和 e: 0 - 一个任务的 CPU 和内存用量 在其执行期间是固定的数值。显然离线作业也受 资源容量的约束。数据集 a 和 c 中任务使用的资源 粒度较小,但实例数量多,而 b 和 d 中任务的 资源粒度较大,但实例数量少。总体而言,a 和 b 的资源总量基本相当,c 和 d 也基本相当,a/b 的资源总量约是 c/d 的 两倍。直觉上 小的实例可能比较容易部署
- 一个任务有 多个实例,实例是资源管理的单元。作业的实例 不是 Pouch 容器。实例一旦部署到某台机器,开始执行后,直到结束退出,期间不发生迁移。任务的实例总数要远大于在线应用的实例总数(数据集 a 最多,有 110 万多个实例)。可以单独为每个实例分配资源,但要使用一些缓存分数的优化技巧;也可以按批次处理。同时,为了与在线应用的 实例 区分,这里将离线任务的若干实例(可以是单个实例)称为一个 批次(Batch),形式是一个四元组
<Task, Machine, BeginTime, Size>,表示部署到某机器(Machine),在某一时刻(BeginTime,分钟)开始执行的离线任务(Task)的若干实例(Size)。这也是离线作业提交文件的格式。 部署机器不同,或开始执行时间不同,都不是同一批次。 - 任务的 执行时间(Duration) 以分钟为单位。在线应用只使用了 98 个点,间隔 15 min 来描述应用的 CPU 和内存分时使用量,但复赛的一个周期要考虑 1470 个点,每分钟一个点(共 24.5 h)。任务的开始和结束时间都是整数分钟
- 任务的 前驱列表 直接在文件中给出来了,但要读入同一作业的所有任务后才能知道后继列表。前驱后继关系使作业的所有任务形成一个 有向无环图(DAG)。一个任务必须等待它的所有前驱都结束后才能开始执行。 如果一个任务没有前驱,就是 起始任务,可以有多个起始任务。没有后继的是 终止任务,同样需要读入同一作业的所有任务后才能知道,也可以有多个。 一个作业内任务之间存在 执行顺序约束。不同作业之间没有这个约束。
作业的资源占用、任务/实例个数、DAG复杂程度、执行时间也都是不均衡的,大部分是较小的作业。
我们可以根据 DAG 计算出作业的 关键路径(Critical Path),以及 最短执行时间。一旦某个关键路径上的任务结束,其后继就可以执行了。同一时段可以有多个任务都在关键路径上。非关键路径上任务 的 最早开始时间(BeginEarliest) 与同时段的关键路径任务 的相同,最晚开始时间(BeginLatest) 加上任务 的执行时间(Duration)后,应与对应关键路径任务 的结束时间(End)相同。 上面计算的都是作业本身的相对时间。一旦确定了作业中某个任务在 1470 分钟周期内的具体开始时刻(绝对时间),其前驱和后继的浮动区间也就随之确定了。
不过,复赛的成本分数公式并 没有涉及 离线作业的等待时间,只要不违反上面提到的 资源约束 和 顺序约束 即可。为了防止过载,让就绪的任务多等一段时间也是可以的。决赛答辩中,有的队伍就只进行了 拓扑排序,没有计算上面提到的关键路径参数。
上面提到,在线应用的 CPU 曲线有明显的峰谷。离线作业(Job)与在线应用(App)混部的主要目标就是 错峰填谷。通常后半夜在线应用的负载很低,这时候来执行离线作业,可以提高集群资源利用率。
应用
复赛的 5 个数据集共用一个在线应用数据,跟 初赛数据集 B 的应用和干扰部分 是 一样的,共 9338 个应用,68224 个实例。 不同数据集的 实例 Id 稍有不同,但 每个应用的实例数量是相同的,因此实例 Id 不同并没有什么实质影响。
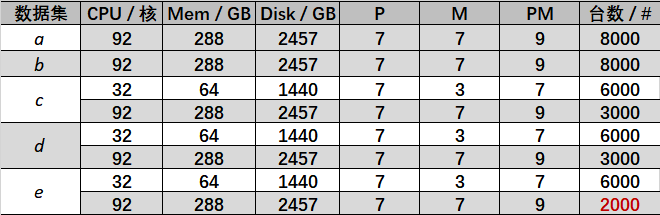
5 个数据集的机器配置和数量有所不同,具体如下表:a,b,e 共 8000 台机器;c 和 d 共 9000 台机器。a 和 b 都只有大型机器,资源总量最多;c,d 和 e 都有 6000 台小型机器,资源总量明显变少了,而且 e 的总量最少。
迁移
初始状态,5 个数据集的所有实例都 已经部署到机器上了。前面提到,可以不考虑初始部署,从空的集群开始执行 装箱 算法,生成优化的 终态。 也可以从 初态 开始,逐步调整实例的部署,这时就不能用装箱了。其实这也是比赛方暗示应该用 局部搜索(Local Search,LS) 算法。
有可能搜索过程很久,实例迁移的动作很多。要达到终态,可以输出搜索的 每一步实例迁移动作,但这可能存在不少冗余动作,即一个实例换了多个部署机器。 另一方面,可以比较 终态和初态的差异 ,生成迁移动作,这需要有足够的空闲资源(机器)进行腾挪,否则可能无法在资源和干扰的约束下到达终态。
复赛对在线应用的迁移增加了限制,采取多轮并发执行。一个迁移动作分为两个阶段:若 机器上的实例 要迁移到 ,先在目标机器 上新建一个实例 ,一轮结束后才删除 上的 ;即过渡阶段 占用了双份资源。可以在搜索的每步都保证这个限制,也可以仅在从终态差异生成迁移动作时考虑。 同一轮次的不同实例迁移可以并发执行。比赛限制的是迁移轮次不超过 3 次,一轮内能迁移的次数则没有限制。
迁移时先新建再删除是合理的,但我认为分轮次迁移并不太合理。相反,限制总的迁移次数更直观。 若资源分配算法比较好,可以将集群保持在比较理想状态,期望重调度需要迁移的实例不太多。
成本公式
复赛还修改了成本公式,将惩罚系数 改为与机器上部署的实例个数 相关: 初赛阶段的成本公式规定如果机器 在时刻 没有实例部署,则 。因为所有应用实例的 CPU 使用量曲线都是>0的,所以只要机器上部署了实例,就不会有 CPU 利用率为 0 的时刻。换句话说,只要机器上有一个时刻的 CPU 利用率为 0,整个机器必然没有实例部署,如果不为 0,必然部署了实例。 复赛中,一台机器可以没有部署任何实例,但部署了离线 Task ,不能按初赛的规定令机器的分数为 0 。 没有 Task 执行的时刻,CPU 利用率为 0,对应的成本分数为 。如果有时刻 CPU 利用率超过了 50%,成本分数仍然是指数增加的。
1.3 链接
- 阿里全球调度算法大赛官网 GSAC 2018,包括赛制,赛题介绍,数据,评分代码,排行榜,答疑论坛
- 初赛解读:专家直播实录(附PPT下载),视频
- 视频:杭州阿里巴巴总部的决赛答辩
- 独家解密:阿里是如何应对超大规模集群资源管理挑战的
- 狮城新加坡完美收官!哪些能人异士参加了阿里全球调度算法大赛初赛?
- 51个国家,2372名选手,20万奖金池,阿里全球调度算法大赛收官
- 月光鸣下:教大家算初赛两份数据的分数下界